Introduction
In the previous articles of the R:case4base series we discussed and learned
- how to reshape data with base R to a form that is practical for our use and
- how to subset data to get the relevant parts of it with base R.
In this one, we will look at aggregation techniques using base R’s stats::aggregate generic function, focusing on the method for data frames. This will allow us to easily and safely create simple aggregations, but also provide a framework for completely custom aggregation functionality defined as separate functions that can be properly documented and unit tested.
Contents
- How to use this article
- Simple aggregations
- Grouping by more variables and small tweaks
- Using aggregate as a framework with custom aggregation functions
- Advanced details of aggregate use
- Aggregate’s methods for other object classes
- Alternatives to base R
- TL;DR - Just want the code
- Exercises
- References
- Exercise answers
How to use this article
- This article is best used with an R session opened in a window next to it - you can test and play with the code yourself instantly while reading. Assuming the author did not fail miserably, the code will work as-is even with vanilla R, no packages or setup needed - it is a
case4baseafter all! - If you have no time for reading, you can click here to get just the code with commentary
First, let’s read in yearly data on gross disposable income of household in the EU countries into R (click here to download) and reshape them to get a nice, long format data to work with:
gdi <- read.csv(
stringsAsFactors = FALSE
, file = "https://jozef.io/post/data/ESA2010_pretty.csv"
)
gdi <- reshape(data = gdi
, direction = "long" # we are going from wide to long
, varying = 2:67 # columns that will be stacked into 1
, idvar = "country" # identifying the subject in rows
)Please note that the figures in the data provided by Eurostat are presented in millions of euros for euro area countries, euro area and EU aggregates and in millions of national currency otherwise. This makes comparing the results between countries difficult, since one would need to do a proper time-dependent currency conversion and potentially inflation adjustment to get comparable data.
The goal of the article is therefore not really in presenting these conrete results, but to focus on the technical aspects and usefulness of the presented methods.
Simple aggregations
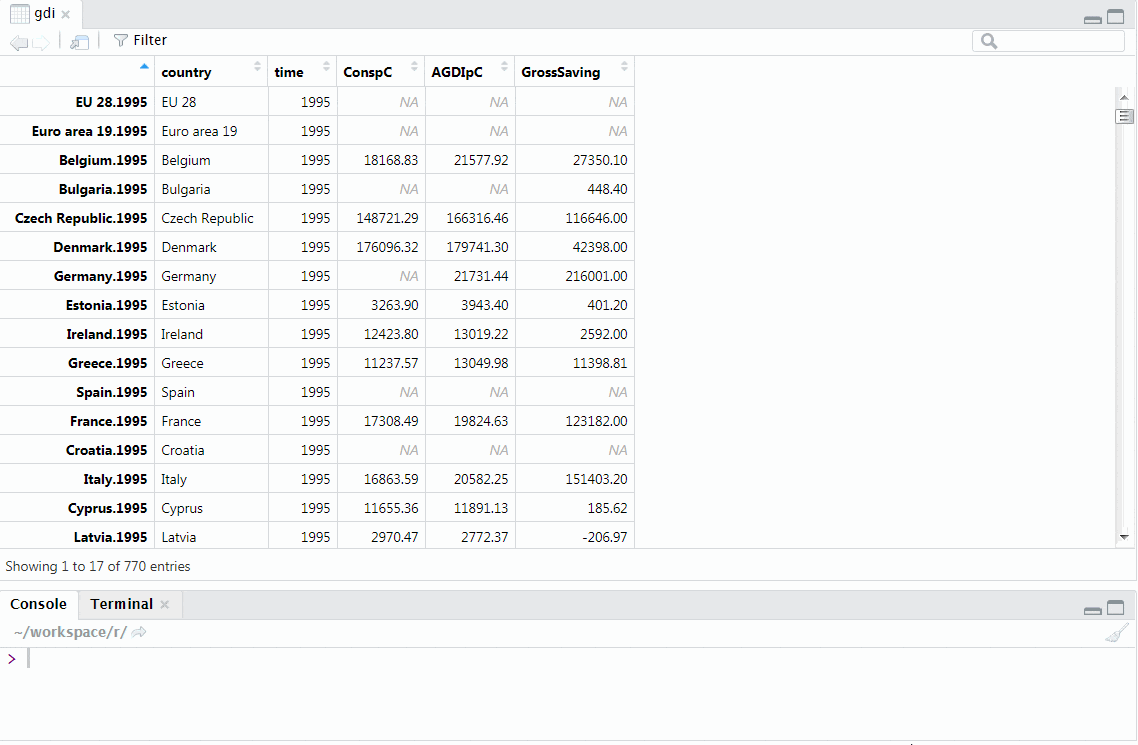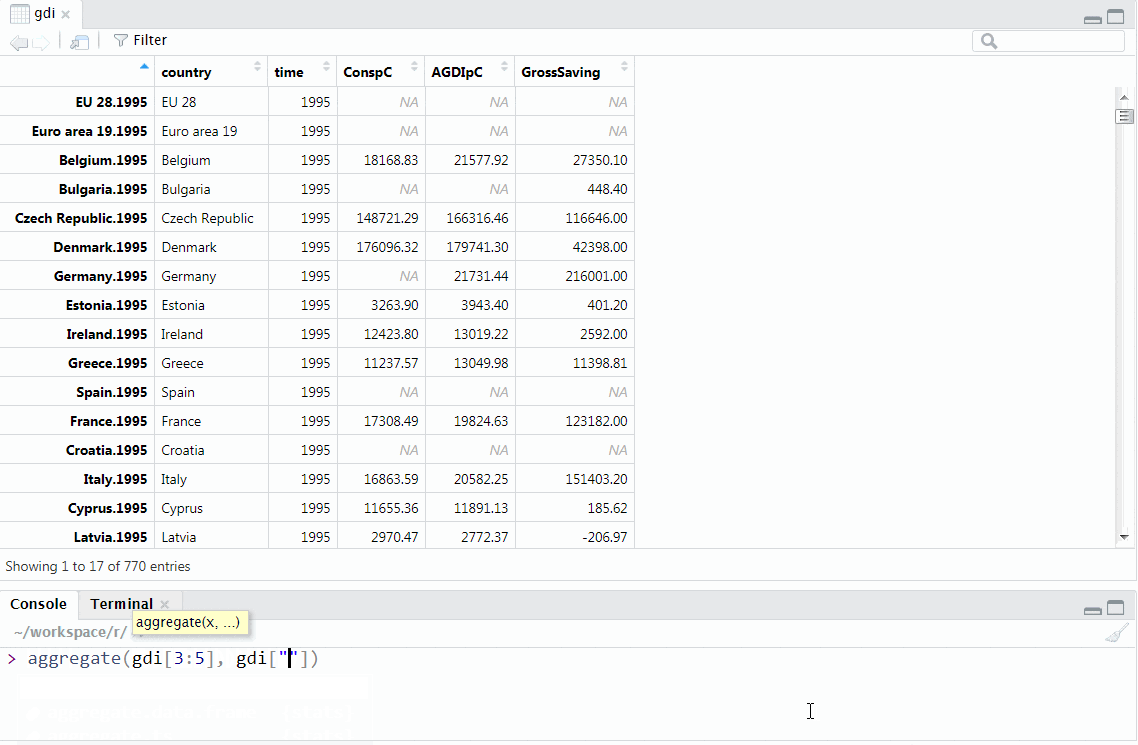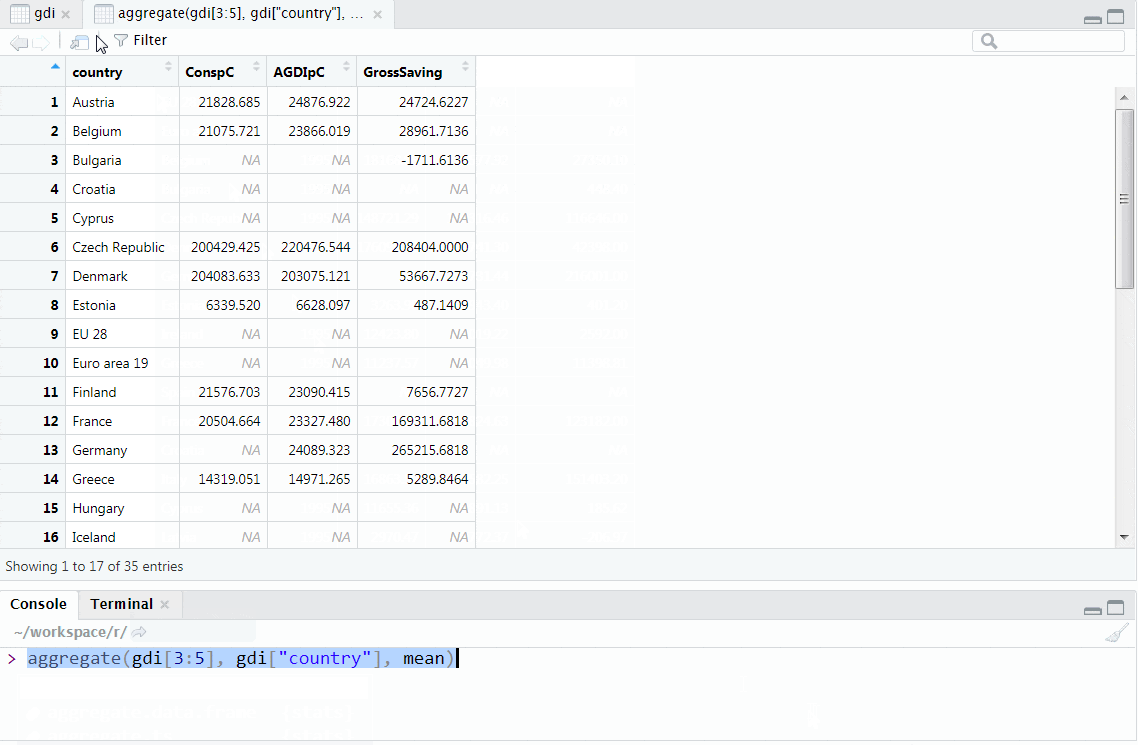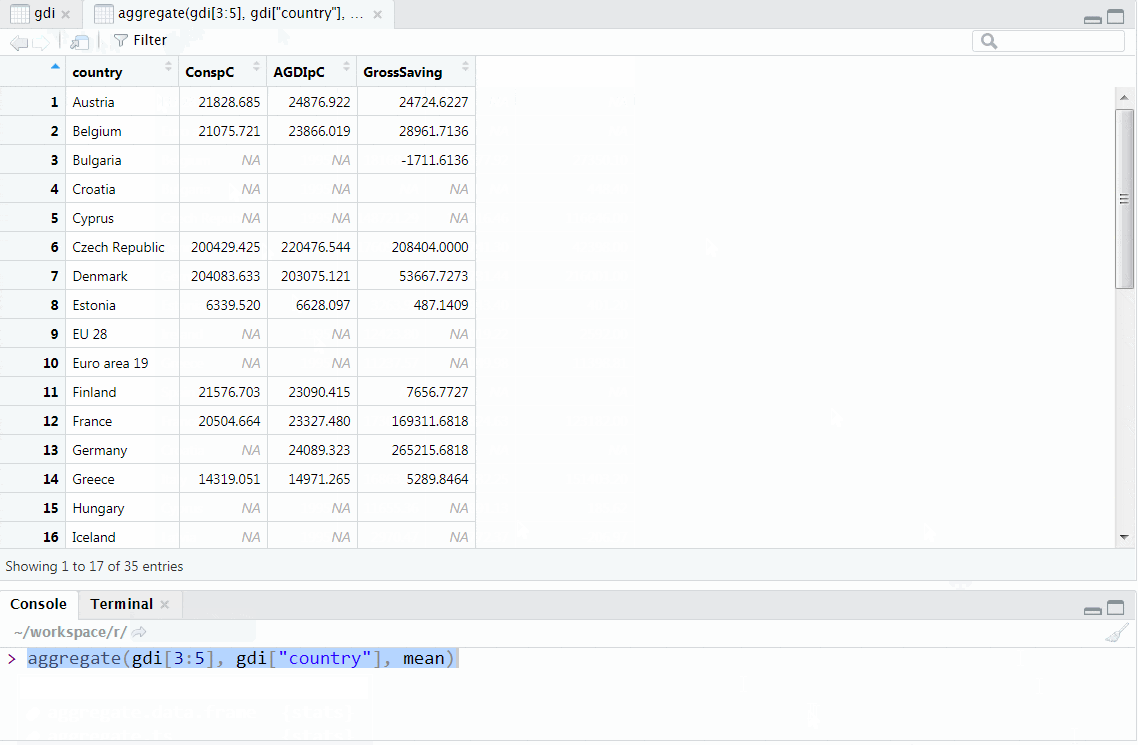
In this paragraph, we will try to show how to perform simple aggregation on data.frames. As the first example, let us look at the mean gross saving across the years per country:
aggregate(x = gdi["GrossSaving"]
, by = list(country = gdi[["country"]])
, FUN = mean
)## country GrossSaving
## 1 Austria 24724.6227
## 2 Belgium 28961.7136
## 3 Bulgaria -1711.6136
## 4 Croatia NA
## 5 Cyprus NA
## 6 Czech Republic 208404.0000
## 7 Denmark 53667.7273
## 8 Estonia 487.1409
## 9 EU 28 NA
## 10 Euro area 19 NA
## 11 Finland 7656.7727
## 12 France 169311.6818
## 13 Germany 265215.6818
## 14 Greece 5289.8464
## 15 Hungary NA
## 16 Iceland NA
## 17 Ireland 5831.3136
## 18 Italy 135086.8591
## 19 Latvia 147.1718
## 20 Lithuania 394.4595
## 21 Luxembourg 2510.5136
## 22 Malta NA
## 23 Netherlands 37810.7727
## 24 Norway 113559.5000
## 25 Poland 45032.8636
## 26 Portugal 9348.6191
## 27 Romania NA
## 28 Serbia NA
## 29 Slovakia 2470.1173
## 30 Slovenia 2346.7668
## 31 Spain NA
## 32 Sweden 207348.7273
## 33 Switzerland 74211.0864
## 34 Turkey NA
## 35 United Kingdom 79609.8636As we can see, we provided 3 arguments to aggregate (specifically the aggregate.data.frame method that gets called if the provided x is a data frame):
x- the data we want to aggregate, in our case theGrossSavingcolumn of thegdidata.frameby- a list of 1 element -countrywhich specifies how the data will be groupedFUN- function which will be used, in our case arithmeticmean
Simple aggregate
We can also see in our results, that for some countries such as Croatia, Cyprus and more, we have NA as a result. This is because numerical operations on vectors that contain even a single NA value will usually return NA as a result. If we want, we can usually work around this by providing an extra na.rm = TRUE argument to the function, which will strip the NA values before computation:
aggregate(x = gdi["GrossSaving"]
, by = list(country = gdi[["country"]])
, FUN = mean
, na.rm = TRUE
)## country GrossSaving
## 1 Austria 24724.6227
## 2 Belgium 28961.7136
## 3 Bulgaria -1711.6136
## 4 Croatia 18301.8727
## 5 Cyprus 438.6838
## 6 Czech Republic 208404.0000
## 7 Denmark 53667.7273
## 8 Estonia 487.1409
## 9 EU 28 924443.4983
## 10 Euro area 19 754148.9800
## 11 Finland 7656.7727
## 12 France 169311.6818
## 13 Germany 265215.6818
## 14 Greece 5289.8464
## 15 Hungary 1220273.5714
## 16 Iceland -336.9933
## 17 Ireland 5831.3136
## 18 Italy 135086.8591
## 19 Latvia 147.1718
## 20 Lithuania 394.4595
## 21 Luxembourg 2510.5136
## 22 Malta NaN
## 23 Netherlands 37810.7727
## 24 Norway 113559.5000
## 25 Poland 45032.8636
## 26 Portugal 9348.6191
## 27 Romania 271.2048
## 28 Serbia NaN
## 29 Slovakia 2470.1173
## 30 Slovenia 2346.7668
## 31 Spain 57683.3333
## 32 Sweden 207348.7273
## 33 Switzerland 74211.0864
## 34 Turkey 129045.3843
## 35 United Kingdom 79609.8636Grouping by more variables and small tweaks
To make things even easier, we can use the fact that data.frames are also lists and we can therefore substitute by = list(country = gdi[["country"]] by a much simpler and easier to read gdi["country"]. Note and be careful that we only use [] for the sub-setting to get the sub-list, as gdi[["country"]] would give us the vector of countries, as well as gdi$country:
is.list(list(country = gdi[["country"]]))## [1] TRUEis.list(gdi["country"])## [1] TRUEis.list(gdi[["country"]])## [1] FALSEWe can also group the data by more than one column, or a column translated in any way that fits our purposes, the only constraint is that the grouping elements (elements of the by argument), are each as long as the variables in the data frame x. And of course we also can aggregate more than 1 column at the same time.
As an example, let us
- calculate the mean not only for each country, but extend the grouping to decades
- calculate the mean for more variables, not just
"GrossSaving"
aggregate(x = gdi[c("ConspC", "AGDIpC", "GrossSaving")]
, by = list(decade = paste0(substr(gdi[["time"]], 1L, 3L), "0s")
, country = gdi[["country"]]
)
, FUN = mean
, na.rm = TRUE
)## decade country ConspC AGDIpC GrossSaving
## 1 1990s Austria 19434.288 22578.640 20956.42000
## 2 2000s Austria 21943.003 25145.214 25327.26000
## 3 2010s Austria 23375.659 26135.279 26555.28571
## 4 1990s Belgium 18938.482 21987.036 25395.72000
## 5 2000s Belgium 21081.202 24088.858 30272.62000
## 6 2010s Belgium 22594.490 24889.807 29636.12857
## 7 1990s Bulgaria 3449.757 3494.050 -68.02000
## 8 2000s Bulgaria 5578.549 5084.613 -2892.99000
## 9 2010s Bulgaria 7813.849 7535.431 -1197.92857
## 10 1990s Croatia NaN NaN NaN
## 11 2000s Croatia 51543.151 54675.474 15148.93750
## 12 2010s Croatia 52515.373 57510.730 26709.70000
## 13 1990s Cyprus 12302.576 12804.322 324.48600
## 14 2000s Cyprus 15719.001 16671.523 727.46300
## 15 2010s Cyprus 15788.383 15973.670 52.55000
## 16 1990s Czech Republic 159897.720 177018.694 132593.40000
## 17 2000s Czech Republic 200904.419 220895.554 204166.20000
## 18 2010s Czech Republic 228702.080 250919.280 268608.42857
## 19 1990s Denmark 182933.412 180861.862 25988.60000
## 20 2000s Denmark 205686.057 202040.782 48128.80000
## 21 2010s Denmark 216901.757 220419.361 81351.28571
## 22 1990s Estonia 3871.640 4249.542 270.28000
## 23 2000s Estonia 6470.004 6500.569 160.78000
## 24 2010s Estonia 7915.886 8509.247 1108.27143
## 25 1990s EU 28 15214.920 16667.920 721765.79000
## 26 2000s EU 28 17108.231 18635.367 890431.08600
## 27 2010s EU 28 18125.639 19647.553 1001986.61714
## 28 1990s Euro area 19 17607.510 19749.530 602634.05000
## 29 2000s Euro area 19 19134.583 21366.280 733063.78800
## 30 2010s Euro area 19 19740.273 21802.314 805915.67286
## 31 1990s Finland 17220.232 18555.942 5659.60000
## 32 2000s Finland 21616.329 23135.134 7536.40000
## 33 2010s Finland 24631.860 26265.441 9255.28571
## 34 1990s France 17903.622 20437.534 127231.80000
## 35 2000s France 20696.734 23594.476 169890.90000
## 36 2010s France 22088.164 25010.304 198541.28571
## 37 1990s Germany NaN 22112.486 215917.60000
## 38 2000s Germany NaN 23846.360 256128.00000
## 39 2010s Germany NaN 25848.440 313411.00000
## 40 1990s Greece 12037.446 13388.490 9475.84600
## 41 2000s Greece 15757.594 16707.839 8902.80000
## 42 2010s Greece 13893.707 13620.999 -2861.51571
## 43 1990s Hungary 1266767.368 1457751.030 868855.20000
## 44 2000s Hungary 1737385.357 1838395.760 1140422.10000
## 45 2010s Hungary 1727120.847 1864085.342 1646208.00000
## 46 1990s Iceland NaN NaN NaN
## 47 2000s Iceland 3665145.798 3246304.470 5208.11000
## 48 2010s Iceland 3491617.010 3112374.812 -11427.20000
## 49 1990s Ireland 14151.552 14664.146 2801.42000
## 50 2000s Ireland 20927.056 21749.417 6089.36000
## 51 2010s Ireland 21803.019 22959.619 7626.88571
## 52 1990s Italy 17703.632 20908.074 140031.20000
## 53 2000s Italy 19631.544 22234.294 143875.11000
## 54 2010s Italy 18584.590 20404.033 119000.54286
## 55 1990s Latvia 3268.952 3188.684 -92.53200
## 56 2000s Latvia 5400.014 5542.577 412.48900
## 57 2010s Latvia 7088.467 6945.319 -60.63571
## 58 1990s Lithuania 3260.052 3348.234 235.99800
## 59 2000s Lithuania 5823.319 5947.266 422.12200
## 60 2010s Lithuania 7934.150 8047.637 468.12857
## 61 1990s Luxembourg 27550.836 31879.426 1411.74000
## 62 2000s Luxembourg 32355.940 37663.168 2240.48000
## 63 2010s Luxembourg 33700.054 40006.649 3681.11429
## 64 1990s Malta NaN NaN NaN
## 65 2000s Malta NaN NaN NaN
## 66 2010s Malta NaN NaN NaN
## 67 1990s Netherlands 18829.144 20298.764 32126.40000
## 68 2000s Netherlands 22457.564 23556.095 34825.10000
## 69 2010s Netherlands 23204.377 24568.551 46136.28571
## 70 1990s Norway 198946.604 207770.146 54321.60000
## 71 2000s Norway 258438.853 269837.239 93655.20000
## 72 2010s Norway 315219.324 334970.457 184307.00000
## 73 1990s Poland 15919.330 18408.280 55897.00000
## 74 2000s Poland 21828.780 22907.936 51046.50000
## 75 2010s Poland 28529.733 28772.321 28681.85714
## 76 1990s Portugal 10704.874 11856.422 8673.37200
## 77 2000s Portugal 12562.477 13609.388 10208.75700
## 78 2010s Portugal 12298.499 13066.471 8602.17000
## 79 1990s Romania 8152.276 8427.888 5.88000
## 80 2000s Romania 13854.047 13125.680 -11695.86000
## 81 2010s Romania 19617.068 20486.043 20437.41667
## 82 1990s Serbia NaN NaN NaN
## 83 2000s Serbia NaN NaN NaN
## 84 2010s Serbia NaN NaN NaN
## 85 1990s Slovakia 5050.218 5647.868 1810.30200
## 86 2000s Slovakia 6824.102 7211.535 2189.37300
## 87 2010s Slovakia 8479.726 8932.469 3342.47714
## 88 1990s Slovenia 8573.522 9491.256 1009.57000
## 89 2000s Slovenia 10719.190 12155.871 2626.34200
## 90 2010s Slovenia 11666.361 12996.130 2902.51429
## 91 1990s Spain 13961.670 15200.950 38715.00000
## 92 2000s Spain 15808.068 17234.555 55932.60000
## 93 2010s Spain 15180.146 16500.587 62894.14286
## 94 1990s Sweden 182324.968 183408.674 68070.60000
## 95 2000s Sweden 223273.148 229308.996 162984.10000
## 96 2010s Sweden 251975.783 273511.021 370211.14286
## 97 1990s Switzerland 41046.446 44855.838 53641.70000
## 98 2000s Switzerland 44297.743 49556.481 69279.00000
## 99 2010s Switzerland 47207.609 54372.377 95949.34286
## 100 1990s Turkey NaN NaN NaN
## 101 2000s Turkey NaN NaN 69969.50000
## 102 2010s Turkey NaN NaN 138891.36500
## 103 1990s United Kingdom 14625.190 15250.624 74342.00000
## 104 2000s United Kingdom 18919.282 19157.107 73031.80000
## 105 2010s United Kingdom 19716.279 20172.029 92769.85714Using aggregate as a framework with custom aggregation functions
Perhaps one of the most useful cases for aggregate is using it as a supporting framework for custom aggregations, since the FUN argument can be set to a function defined to suit specific purposes. This provides a very flexible environment where one can
- implement the custom aggregation functions in the most suitable way for the purpose
- have unit testing for those functions
- documentation and other aspects of implementation in place
And use the aggregate as a reliable executor for such functionality, all using standard base R evaluation principles. An over-simplified example of the above approach could be the following:
We define the aggregation function dummyaggfun
dummyaggfun <- function(v) {
c(max = max(v)
, min = min(v)
, rng = max(v) - min(v)
)
}And apply the aggregation
aggregate(gdi["GrossSaving"]
, by = list(decade = paste0(substr(gdi[["time"]], 1L, 3L), "0s")
, country = gdi[["country"]]
)
, FUN = dummyaggfun
)## decade country GrossSaving.max GrossSaving.min GrossSaving.rng
## 1 1990s Austria 23226.80 19097.10 4129.70
## 2 2000s Austria 31618.00 19897.90 11720.10
## 3 2010s Austria 28755.60 25194.20 3561.40
## 4 1990s Belgium 27350.10 24448.40 2901.70
## 5 2000s Belgium 39041.60 25650.80 13390.80
## 6 2010s Belgium 33126.40 27251.20 5875.20
## 7 1990s Bulgaria 448.40 -483.00 931.40
## 8 2000s Bulgaria -758.60 -7200.60 6442.00
## 9 2010s Bulgaria 2925.80 -4525.60 7451.40
## 10 1990s Croatia NA NA NA
## 11 2000s Croatia NA NA NA
## 12 2010s Croatia NA NA NA
## 13 1990s Cyprus 545.50 185.62 359.88
## 14 2000s Cyprus 1194.23 280.04 914.19
## 15 2010s Cyprus NA NA NA
## 16 1990s Czech Republic 145286.00 116646.00 28640.00
## 17 2000s Czech Republic 295156.00 156060.00 139096.00
## 18 2010s Czech Republic 293141.00 246605.00 46536.00
## 19 1990s Denmark 42398.00 9694.00 32704.00
## 20 2000s Denmark 72548.00 15456.00 57092.00
## 21 2010s Denmark 111688.00 36971.00 74717.00
## 22 1990s Estonia 401.20 200.20 201.00
## 23 2000s Estonia 1115.10 -278.30 1393.40
## 24 2010s Estonia 1415.10 839.50 575.60
## 25 1990s EU 28 NA NA NA
## 26 2000s EU 28 1077659.22 769059.51 308599.71
## 27 2010s EU 28 1029579.38 976054.92 53524.46
## 28 1990s Euro area 19 NA NA NA
## 29 2000s Euro area 19 879005.73 596298.12 282707.61
## 30 2010s Euro area 19 822350.15 781605.58 40744.57
## 31 1990s Finland 6772.00 4436.00 2336.00
## 32 2000s Finland 10986.00 6200.00 4786.00
## 33 2010s Finland 10801.00 7534.00 3267.00
## 34 1990s France 131350.00 119588.00 11762.00
## 35 2000s France 206161.00 136627.00 69534.00
## 36 2010s France 206511.00 191738.00 14773.00
## 37 1990s Germany 217330.00 214836.00 2494.00
## 38 2000s Germany 291363.00 216433.00 74930.00
## 39 2010s Germany 345523.00 292290.00 53233.00
## 40 1990s Greece 11398.81 8234.04 3164.77
## 41 2000s Greece 11510.19 6390.06 5120.13
## 42 2010s Greece 2897.71 -7727.10 10624.81
## 43 1990s Hungary 1012178.00 710576.00 301602.00
## 44 2000s Hungary 1614306.00 788873.00 825433.00
## 45 2010s Hungary NA NA NA
## 46 1990s Iceland NA NA NA
## 47 2000s Iceland 88500.00 -52886.40 141386.40
## 48 2010s Iceland NA NA NA
## 49 1990s Ireland 3219.60 2592.00 627.60
## 50 2000s Ireland 11973.40 1384.10 10589.30
## 51 2010s Ireland 9545.40 6374.60 3170.80
## 52 1990s Italy 163452.00 116367.20 47084.80
## 53 2000s Italy 156700.60 111087.70 45612.90
## 54 2010s Italy 124778.90 104720.00 20058.90
## 55 1990s Latvia 36.17 -206.97 243.14
## 56 2000s Latvia 1922.58 -81.56 2004.14
## 57 2010s Latvia 620.12 -555.45 1175.57
## 58 1990s Lithuania 610.73 -78.62 689.35
## 59 2000s Lithuania 1003.24 -719.82 1723.06
## 60 2010s Lithuania 1516.18 -119.85 1636.03
## 61 1990s Luxembourg 1488.10 1344.60 143.50
## 62 2000s Luxembourg 2964.30 1584.80 1379.50
## 63 2010s Luxembourg 4119.00 3192.70 926.30
## 64 1990s Malta NA NA NA
## 65 2000s Malta NA NA NA
## 66 2010s Malta NA NA NA
## 67 1990s Netherlands 34110.00 28988.00 5122.00
## 68 2000s Netherlands 47342.00 28712.00 18630.00
## 69 2010s Netherlands 50314.00 40945.00 9369.00
## 70 1990s Norway 66426.00 42704.00 23722.00
## 71 2000s Norway 140538.00 51542.00 88996.00
## 72 2010s Norway 253022.00 117285.00 135737.00
## 73 1990s Poland 69410.00 43081.00 26329.00
## 74 2000s Poland 84850.00 27414.00 57436.00
## 75 2010s Poland 49574.00 14823.00 34751.00
## 76 1990s Portugal 9717.60 7907.00 1810.60
## 77 2000s Portugal 13217.79 8530.86 4686.93
## 78 2010s Portugal 11929.76 6245.18 5684.58
## 79 1990s Romania 2749.90 -2122.40 4872.30
## 80 2000s Romania 1146.30 -24932.80 26079.10
## 81 2010s Romania NA NA NA
## 82 1990s Serbia NA NA NA
## 83 2000s Serbia NA NA NA
## 84 2010s Serbia NA NA NA
## 85 1990s Slovakia 2073.54 1132.87 940.67
## 86 2000s Slovakia 3119.07 1697.54 1421.53
## 87 2010s Slovakia 4622.03 2627.62 1994.41
## 88 1990s Slovenia 1214.62 731.94 482.68
## 89 2000s Slovenia 3578.14 1587.45 1990.69
## 90 2010s Slovenia 3175.60 2337.12 838.48
## 91 1990s Spain NA NA NA
## 92 2000s Spain 93604.00 38368.00 55236.00
## 93 2010s Spain 74681.00 53982.00 20699.00
## 94 1990s Sweden 100539.00 50227.00 50312.00
## 95 2000s Sweden 257867.00 85342.00 172525.00
## 96 2010s Sweden 452834.00 280354.00 172480.00
## 97 1990s Switzerland 56395.80 51875.60 4520.20
## 98 2000s Switzerland 83474.60 59724.20 23750.40
## 99 2010s Switzerland 104819.20 84475.00 20344.20
## 100 1990s Turkey NA NA NA
## 101 2000s Turkey NA NA NA
## 102 2010s Turkey NA NA NA
## 103 1990s United Kingdom 84296.00 55971.00 28325.00
## 104 2000s United Kingdom 102670.00 58101.00 44569.00
## 105 2010s United Kingdom 126386.00 68648.00 57738.00Advanced details of aggregate use
Examining the code of aggregate.data.frame will give us a good picture of how the function operates. This could be roughly described in the following way, abstracting from the defensive programming aspects and details and focusing on the functionality itself:
- create
grp- group labels that are (most likely) numbers stored ascharacterby factorizing the elements ofby - create
y- adata.framewith the data grouping resulting from processingby, to which the results will be binded - take the input data
x(coerced to adata.frame) and column by columnsplitthe data into groups according togrp - apply
FUN(that was retrieved bymatch.fun) on the results of thesplit, assign the results intoz - bind the
ythat has the group labels withzthat has the results
Providing the
FUNargumentOne specific should be noted - providing
FUNas a character string (name of the function, e.g.FUN = "mean") will trigger the non-standard evaluation part of code inmatch.fun, which we may like to avoid. This is easily achieved by providing theFUNargument with the function diretly, not via the function’s name (e.g.FUN = mean) as in that casematch.funjust returns the providedFUNwithout further changes
Argument structure of
FUNThe value returned from
splitis a list of vectors containing the values for the groups. TheFUNis provided with the elements of that list vialapply, which are vectors. This is helpful for the setup of the customFUN. We can also take advantage of the...concept and dedicate a part of theFUNcode to process more provided arguments.
Aggregate’s methods for other object classes
So far we have mostly used the aggregate.data.frame method, however aggregate is a generic function with methods for multiple classes of objects, here is a very quick overview:
aggregate.default- the default method, which uses the time series method ifxis a time series, and otherwise coercesxto adata.frameand calls thedata.framemethodaggregate.ts- the time series method, is further discussed in R’s help on?aggregate. Investigation of the code is also very advisable.aggregate.formula- the formula method, is a standard formula interface toaggregate.data.frameaggregate.data.frame- is discussed in this article
Alternatives to base R
- dplyr::summarize and friends
- using data.table
TL;DR - Just want the code
No time for reading? Click here to get just the code with commentary
Exercises
- Looking at the
aggregate(state.x77, list(Region = state.region), mean)example in?aggregate, how does R know how to match the states to the regions? Would the example still work if the data instate.x77were sorted differently? - What is the difference between
aggregate(x = gdi["GrossSaving"], by = gdi["country"], FUN = mean)andaggregate(x = gdi[["GrossSaving"]], by = gdi["country"], FUN = mean). What is the issue with the latter? Looking at the code ofaggregate.data.frame, why does the latter still work?
References
- aggregate at rdocumentation.org
- split at rdocumentation.org
- discussion on
...(ellipsis) on stack overflow - original eurostat data source