Introduction
In this post in the R:case4base series we will look at string manipulation with base R, and provide an overview of a wide range of functions for our string working needs.
We will use simple examples to learn to perform basic string operations, concatenate strings, work with substrings, switch cases, quote, find and replace within strings and more. Some interesting bonuses will also be included.
As always, some popular alternatives to base R will also be suggested and many useful references provided for further reading.
Contents
Quick overview of the very basics
This post is aimed to serve as an overview of functionality provided by base R to work with strings. Note that the term “string” is used somewhat loosely and refers to character vectors and character strings. In R documentation, references to character string, refer to character vectors of length 1.
Also since this is an overview, we will not examine the details of the functions, but rather list examples with simple, intuitive explanations trading off technical precision.
# String constants can be assigned using
# double quotes
a <- "this is a character string"
# or single quotes
b <- 'this is a character string, too'
# To use literal quotes, we can escape with `\`:
c <- "this is \"it\""
# To make a character vector with multiple elements:
d <- c("this", "vector", "has", "five", "elements")
# To get the length of a character vector
# (how many elements are in a character vector)
length(d)## [1] 5# To get the number of characters in elemets of a vector
# ("how many characters in each of the elements")
nchar(d)## [1] 4 6 3 4 8# To create a missing character value
NA_character_## [1] NA# To test if an object is a character vector
is.character("is this a character vector?")## [1] TRUE# To convert other objects to character vectors
# Can surprise the unwary
as.character(c(
42,
Sys.time(),
factor("A", levels = LETTERS)
))## [1] "42" "1543050000" "1"# One of the ways to output a vector is `cat`
cat("Show me this")## Show me this# To include line breaks use `"\n"`
# To include tabs use `"\t"`:
cat("Break\ta\ta\nline")## Break a a
## line# When in doubt about an object
# str or summary may help
weirdList <- list(
"What is this?",
Sys.time(),
b = 5L,
c = c("one", 2),
d = factor(c("red", "blue")),
e = NA_character_,
f = NA_integer_
)
str(weirdList)## List of 7
## $ : chr "What is this?"
## $ : POSIXct[1:1], format: "2018-11-24 09:00:00"
## $ b: int 5
## $ c: chr [1:2] "one" "2"
## $ d: Factor w/ 2 levels "blue","red": 2 1
## $ e: chr NA
## $ f: int NAsummary(weirdList)## Length Class Mode
## 1 -none- character
## 1 POSIXct numeric
## b 1 -none- numeric
## c 2 -none- character
## d 2 factor numeric
## e 1 -none- character
## f 1 -none- numericString concatenation
String concatenation is the process of “joining” two strings together and one the most common operations.
Simple concatenation
# We will use these vectors for our examples:
1:3## [1] 1 2 3month.name## [1] "January" "February" "March" "April" "May"
## [6] "June" "July" "August" "September" "October"
## [11] "November" "December"# Use paste to concatenate
# R recycles 1:3 4 times to fit the length of month.name
paste(1:3, month.name)## [1] "1 January" "2 February" "3 March" "1 April" "2 May"
## [6] "3 June" "1 July" "2 August" "3 September" "1 October"
## [11] "2 November" "3 December"# Specify the sep argument to
# separate the elements differently
paste(1:3, month.name, sep = ": ")## [1] "1: January" "2: February" "3: March" "1: April"
## [5] "2: May" "3: June" "1: July" "2: August"
## [9] "3: September" "1: October" "2: November" "3: December"# A shorthard for sep = ""
paste0(1:3, month.name)## [1] "1January" "2February" "3March" "1April" "2May"
## [6] "3June" "1July" "2August" "3September" "1October"
## [11] "2November" "3December"# Alternatively, sprintf is very useful
sprintf("%s: %s", 1:3, month.name)## [1] "1: January" "2: February" "3: March" "1: April"
## [5] "2: May" "3: June" "1: July" "2: August"
## [9] "3: September" "1: October" "2: November" "3: December"Concatenate a vector into a single character string
# Provide the collapse argument to paste
# to get a character string (length 1 vector):
paste(1:3, month.name, sep = ": ", collapse = ", ")## [1] "1: January, 2: February, 3: March, 1: April, 2: May, 3: June, 1: July, 2: August, 3: September, 1: October, 2: November, 3: December"# Or, use toString
toString(paste(1:3, month.name, sep = ": "))## [1] "1: January, 2: February, 3: March, 1: April, 2: May, 3: June, 1: July, 2: August, 3: September, 1: October, 2: November, 3: December"String manipulation and properties
String lengths
# How many elements does a vector have?
length(month.name)## [1] 12# To get the number of characters in elemets of a vector
# ("how many characters in each of the elements?")
nchar(month.name)## [1] 7 8 5 5 3 4 4 6 9 7 8 8# Are the elements non-empty strings?
nzchar(month.name)## [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUESwitching to upper/lower case
# Switch to all lower case
tolower(month.name)## [1] "january" "february" "march" "april" "may"
## [6] "june" "july" "august" "september" "october"
## [11] "november" "december"# Switch to all upper case
toupper(month.name)## [1] "JANUARY" "FEBRUARY" "MARCH" "APRIL" "MAY"
## [6] "JUNE" "JULY" "AUGUST" "SEPTEMBER" "OCTOBER"
## [11] "NOVEMBER" "DECEMBER"# Casefold is a wrapper for S-PLUS compatibility
casefold(month.name, upper = FALSE)## [1] "january" "february" "march" "april" "may"
## [6] "june" "july" "august" "september" "october"
## [11] "november" "december"casefold(month.name, upper = TRUE)## [1] "JANUARY" "FEBRUARY" "MARCH" "APRIL" "MAY"
## [6] "JUNE" "JULY" "AUGUST" "SEPTEMBER" "OCTOBER"
## [11] "NOVEMBER" "DECEMBER"# Also, custom translation:
chartr("OIZEASGTC", "01234567(" , toupper(month.name))## [1] "J4NU4RY" "F3BRU4RY" "M4R(H" "4PR1L" "M4Y"
## [6] "JUN3" "JULY" "4U6U57" "53P73MB3R" "0(70B3R"
## [11] "N0V3MB3R" "D3(3MB3R"Removing white spaces
# Remove all leading and trailing whitespaces
trimws(" This has trailing spaces. ")## [1] "This has trailing spaces."# Remove leading whitespaces
trimws(" This has trailing spaces. ", which = "left")## [1] "This has trailing spaces. "# Remove trailing whitespaces
trimws(" This has trailing spaces. ", which = "right")## [1] " This has trailing spaces."Encoding conversion
# Convert a character vector between encodings
iconv("šibrinkuje", "UTF-8", "ASCII", "?")## [1] "??ibrinkuje"Quoting
# Quoting text for fancier priting:
sQuote(month.name)## [1] "'January'" "'February'" "'March'" "'April'" "'May'"
## [6] "'June'" "'July'" "'August'" "'September'" "'October'"
## [11] "'November'" "'December'"dQuote(month.name)## [1] "\"January\"" "\"February\"" "\"March\"" "\"April\""
## [5] "\"May\"" "\"June\"" "\"July\"" "\"August\""
## [9] "\"September\"" "\"October\"" "\"November\"" "\"December\""# Not to be confused with quoting strings for passing to OS shell
system(paste("echo", shQuote("Weird\nstuff")))
# Also not be confused with quoting expressions
str(quote(1 + 1))## language 1 + 1Retrieving and working with substrings
# Get the first three characters from all the month.names
substr(month.name, 1, 3)## [1] "Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul" "Aug" "Sep" "Oct" "Nov"
## [12] "Dec"# Get the last three characters from all the month.names
substr(month.name, nchar(month.name) - 2, nchar(month.name))## [1] "ary" "ary" "rch" "ril" "May" "une" "uly" "ust" "ber" "ber" "ber"
## [12] "ber"# Wrapper around substr for S Compability:
substring(month.name, 1, 3)## [1] "Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul" "Aug" "Sep" "Oct" "Nov"
## [12] "Dec"# Check whether elements start with a string
startsWith(month.name, "J")## [1] TRUE FALSE FALSE FALSE FALSE TRUE TRUE FALSE FALSE FALSE FALSE
## [12] FALSE# Check whether elements end with a string
endsWith(month.name, "ember")## [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE TRUE
## [12] TRUE# Trim character strings to specified display widths.
strtrim(month.name, 3)## [1] "Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul" "Aug" "Sep" "Oct" "Nov"
## [12] "Dec"# Abbreviate strings to at least minlength characters
abbreviate(month.name, minlength = 3)## January February March April May June July
## "Jnr" "Fbr" "Mrc" "Apr" "May" "Jun" "Jly"
## August September October November December
## "Ags" "Spt" "Oct" "Nvm" "Dcm"Basic pattern matching and replacement
Pattern matching and replacement using regular expressions in an extremely powerful feature, however it is out of scope of this overview to cover them.
Check the references for better resources if you are interested. A lot more useful detail can also be found in R’s documentation.
The following is just to show very basic use and list useful functions.
Replace substring with other strings
myStrings <- paste(1:3, month.name, sep = ". ")
# Replace all ones with zeros:
# fixed will match the first argument as is
gsub("1", "0", myStrings, fixed = TRUE)## [1] "0. January" "2. February" "3. March" "0. April"
## [5] "2. May" "3. June" "0. July" "2. August"
## [9] "3. September" "0. October" "2. November" "3. December"# Replace only the first "a" in each for "A"
sub("a", "A", myStrings, fixed = TRUE)## [1] "1. JAnuary" "2. FebruAry" "3. MArch" "1. April"
## [5] "2. MAy" "3. June" "1. July" "2. August"
## [9] "3. September" "1. October" "2. November" "3. December"# Replace any number with 0
# note that the fixed argument is now FALSE (default)
gsub("[0-9]", "0", myStrings)## [1] "0. January" "0. February" "0. March" "0. April"
## [5] "0. May" "0. June" "0. July" "0. August"
## [9] "0. September" "0. October" "0. November" "0. December"# Replace literal dots with 0
gsub(".", "0", myStrings, fixed = TRUE)## [1] "10 January" "20 February" "30 March" "10 April"
## [5] "20 May" "30 June" "10 July" "20 August"
## [9] "30 September" "10 October" "20 November" "30 December"# This will replace all characters (except "\n") with zeros
gsub(".", "0", myStrings)## [1] "0000000000" "00000000000" "00000000" "00000000"
## [5] "000000" "0000000" "0000000" "000000000"
## [9] "000000000000" "0000000000" "00000000000" "00000000000"# Also replace literal dots but without "fixed = TRUE"
# by escaping "." using "\\." instead.
# This will treat "." literally instead of its special meaning
gsub("\\.", "0", myStrings)## [1] "10 January" "20 February" "30 March" "10 April"
## [5] "20 May" "30 June" "10 July" "20 August"
## [9] "30 September" "10 October" "20 November" "30 December"Check if a pattern is present within elements of a character vector
myStrings <- paste(1:3, month.name, sep = ". ")
# Is a pattern present (returns a logical vector)?
grepl("ember", myStrings)## [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE TRUE
## [12] TRUE# In which elements is a pattern present (returns indices)?
grep("ember", myStrings)## [1] 9 11 12# In which elements is a pattern present (returns the values)?
grep("ember", myStrings, value = TRUE)## [1] "3. September" "2. November" "3. December"Check where the matches are within the elements of a character vector
myStrings <- paste(1:3, month.name, sep = ". ")
# Where is the first "a" located in each of the elements?
# pattern if not found in that element, returns -1
regexpr("a", myStrings)## [1] 5 9 5 -1 5 -1 -1 -1 -1 -1 -1 -1
## attr(,"match.length")
## [1] 1 1 1 -1 1 -1 -1 -1 -1 -1 -1 -1
## attr(,"useBytes")
## [1] TRUE# Where are all the "a" located in each of the elements?
# If pattern not found in that element, returns -1
gregexpr("a", myStrings)## [[1]]
## [1] 5 8
## attr(,"match.length")
## [1] 1 1
## attr(,"useBytes")
## [1] TRUE
##
## [[2]]
## [1] 9
## attr(,"match.length")
## [1] 1
## attr(,"useBytes")
## [1] TRUE
##
## [[3]]
## [1] 5
## attr(,"match.length")
## [1] 1
## attr(,"useBytes")
## [1] TRUE
##
## [[4]]
## [1] -1
## attr(,"match.length")
## [1] -1
## attr(,"useBytes")
## [1] TRUE
##
## [[5]]
## [1] 5
## attr(,"match.length")
## [1] 1
## attr(,"useBytes")
## [1] TRUE
##
## [[6]]
## [1] -1
## attr(,"match.length")
## [1] -1
## attr(,"useBytes")
## [1] TRUE
##
## [[7]]
## [1] -1
## attr(,"match.length")
## [1] -1
## attr(,"useBytes")
## [1] TRUE
##
## [[8]]
## [1] -1
## attr(,"match.length")
## [1] -1
## attr(,"useBytes")
## [1] TRUE
##
## [[9]]
## [1] -1
## attr(,"match.length")
## [1] -1
## attr(,"useBytes")
## [1] TRUE
##
## [[10]]
## [1] -1
## attr(,"match.length")
## [1] -1
## attr(,"useBytes")
## [1] TRUE
##
## [[11]]
## [1] -1
## attr(,"match.length")
## [1] -1
## attr(,"useBytes")
## [1] TRUE
##
## [[12]]
## [1] -1
## attr(,"match.length")
## [1] -1
## attr(,"useBytes")
## [1] TRUE# Where are all the "a" located in the first element?
gregexpr("a", myStrings[1])## [[1]]
## [1] 5 8
## attr(,"match.length")
## [1] 1 1
## attr(,"useBytes")
## [1] TRUE# or also
gregexpr("a", myStrings)[[1]]## [1] 5 8
## attr(,"match.length")
## [1] 1 1
## attr(,"useBytes")
## [1] TRUEWe skip regexec here as parenthesized sub-expressions are very much out of scope of this post.
Extract the matching substrings
The above regexpr() and gregexpr() tell us where the patterns we are looking for are located. It is often useful to extract the actual substrings that are at those locations and regmatches() does that for us:
myStrings <- paste(1:3, month.name, sep = ". ")
# Find substrings that start with 1 or 2 and end
# in "ber" within myStrings
regmatches(
myStrings,
regexpr("^[1-2].*ber$", myStrings)
)## [1] "1. October" "2. November"# Alternatively, the same as a list of the same
# length as myStrings
regmatches(
myStrings,
gregexpr("^[1-2].*ber$", myStrings)
)## [[1]]
## character(0)
##
## [[2]]
## character(0)
##
## [[3]]
## character(0)
##
## [[4]]
## character(0)
##
## [[5]]
## character(0)
##
## [[6]]
## character(0)
##
## [[7]]
## character(0)
##
## [[8]]
## character(0)
##
## [[9]]
## character(0)
##
## [[10]]
## [1] "1. October"
##
## [[11]]
## [1] "2. November"
##
## [[12]]
## character(0)# We can also get the non-matched substrings
# using invert = TRUE
regmatches(
myStrings,
regexpr("^[1-2].*ber$", myStrings),
invert = TRUE
)## [[1]]
## [1] "1. January"
##
## [[2]]
## [1] "2. February"
##
## [[3]]
## [1] "3. March"
##
## [[4]]
## [1] "1. April"
##
## [[5]]
## [1] "2. May"
##
## [[6]]
## [1] "3. June"
##
## [[7]]
## [1] "1. July"
##
## [[8]]
## [1] "2. August"
##
## [[9]]
## [1] "3. September"
##
## [[10]]
## [1] "" ""
##
## [[11]]
## [1] "" ""
##
## [[12]]
## [1] "3. December"Bonuses
Strings
# The Levenshtein distance between strings
adist(c("lazy", "lasso", "lassie"), c("lazy", "lazier", "laser"))## [,1] [,2] [,3]
## [1,] 0 3 3
## [2,] 3 4 2
## [3,] 4 3 3# Repeat elements of a character vector a given number of times
strrep(c(":)", ":P ", ";) "), 1:3)## [1] ":)" ":P :P " ";) ;) ;) "# Convert strings to integers of a given base
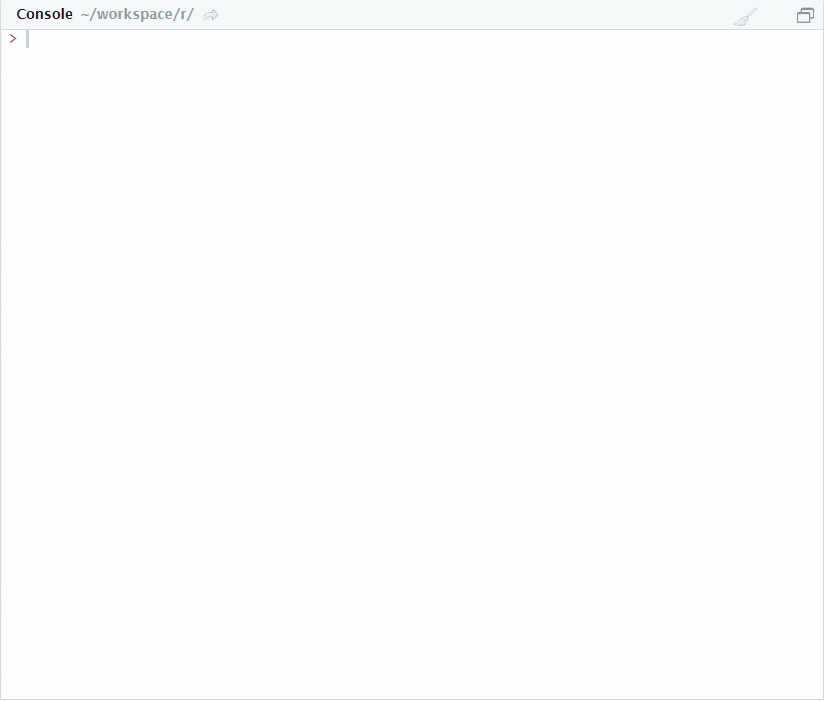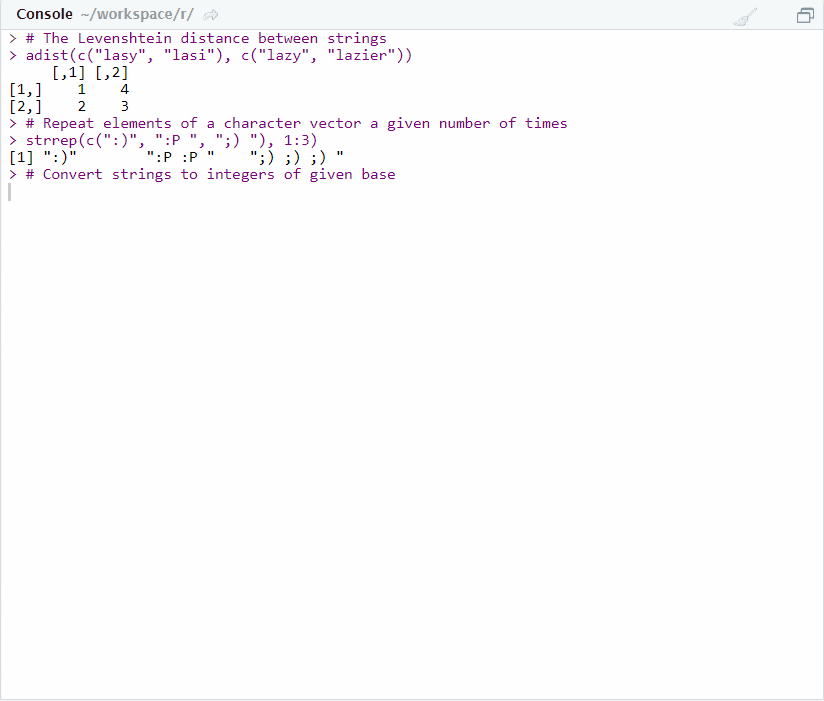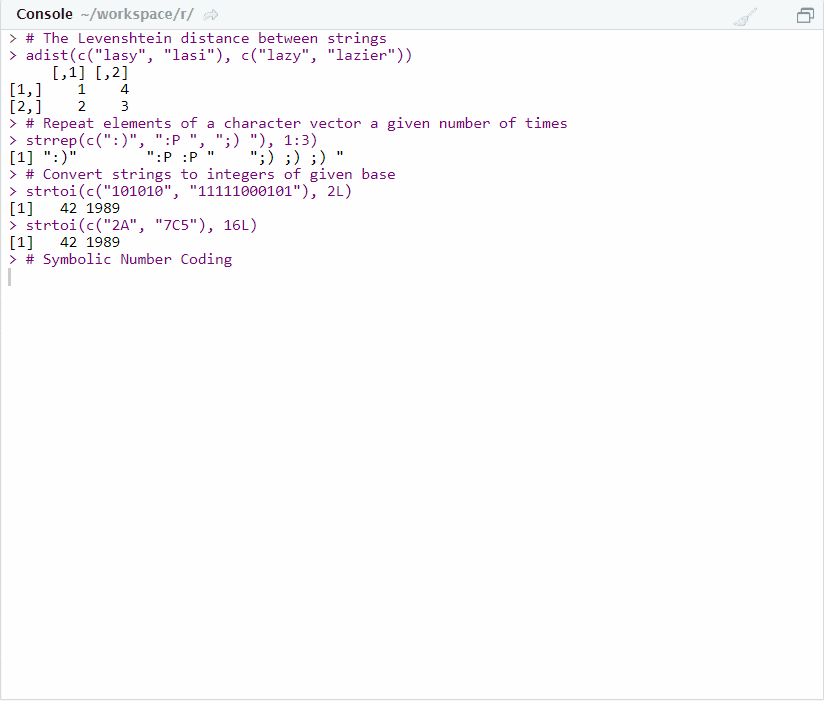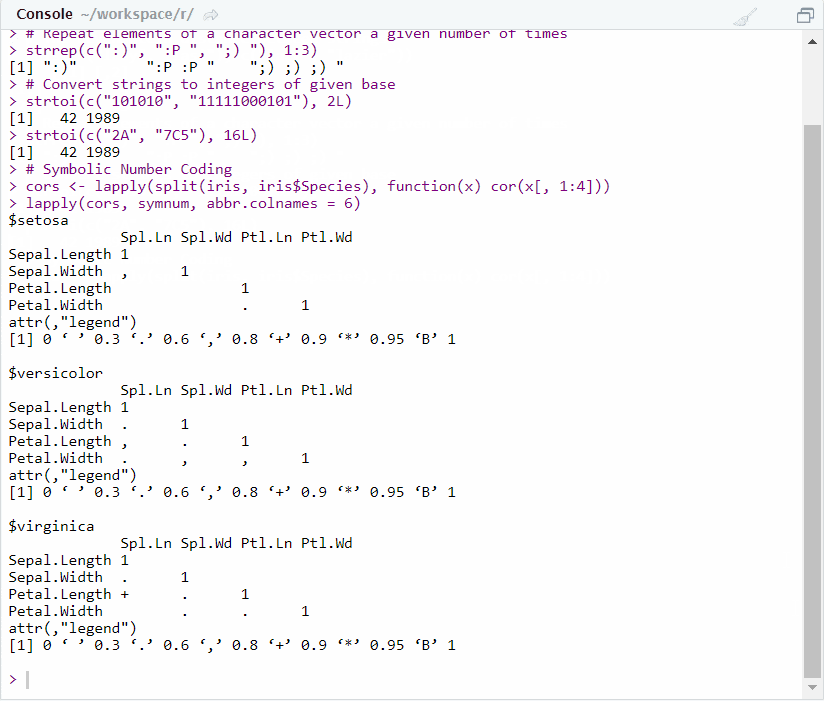
strtoi(c("101010", "11111000101"), base = 2L)## [1] 42 1989strtoi(c("2A", "7C5"), base = 16L)## [1] 42 1989# Symbolic Number Coding
cors <- lapply(split(iris, iris$Species), function(x) cor(x[, 1:4]))
lapply(cors, symnum, abbr.colnames = 6)## $setosa
## Spl.Ln Spl.Wd Ptl.Ln Ptl.Wd
## Sepal.Length 1
## Sepal.Width , 1
## Petal.Length 1
## Petal.Width . 1
## attr(,"legend")
## [1] 0 ' ' 0.3 '.' 0.6 ',' 0.8 '+' 0.9 '*' 0.95 'B' 1
##
## $versicolor
## Spl.Ln Spl.Wd Ptl.Ln Ptl.Wd
## Sepal.Length 1
## Sepal.Width . 1
## Petal.Length , . 1
## Petal.Width . , , 1
## attr(,"legend")
## [1] 0 ' ' 0.3 '.' 0.6 ',' 0.8 '+' 0.9 '*' 0.95 'B' 1
##
## $virginica
## Spl.Ln Spl.Wd Ptl.Ln Ptl.Wd
## Sepal.Length 1
## Sepal.Width . 1
## Petal.Length + . 1
## Petal.Width . . 1
## attr(,"legend")
## [1] 0 ' ' 0.3 '.' 0.6 ',' 0.8 '+' 0.9 '*' 0.95 'B' 1Alternatives to base R
Using the tidyverse’s stringr and glue
Using stringi
- Stringi is an R package for very fast, correct, consistent, and convenient string/text processing in each locale and any native character encoding.
TL;DR - Just want the code
No time for reading? Click here to get just the code with commentary
References
- Pattern Matching And Replacement R documentation
- Regular Expressions As Used In R
- Regular Expressions in R Programming for Data Science
- Regular Expressions (video)
- Handling Strings with R by Gaston Sanchez
- Cheat Sheet for basic regular expressions in R