Introduction
Data manipulation and aggregation is one of the classic tasks anyone working with data will come across. We of course can perform data transformation and aggregation with base R, but when speed and memory efficiency come into play, data.table is my package of choice.
In this post we will look at of the fresh and very useful functionality that came to data.table only last year - grouping sets, enabling us, for example, to create pivot table-like reports with sub-totals and grand total quickly and easily.
Contents
Basic by-group summaries with data.table
To showcase the functionality, we will use a very slightly modified dataset provided by Hadley Wickham’s nycflights13 package, mainly the flights data frame. Lets prepare a small dataset suitable for the showcase:
library(data.table)
dataurl <- "https://jozef.io/post/data/"
flights <- readRDS(url(paste0(dataurl, "r006/flights.rds")))
flights <- as.data.table(flights)[month < 3]Now, for those unfamiliar with data table, to create a summary of distances flown per month and originating airport with data.table, we could simply use:
flights[, sum(distance), by = c("month", "origin")]## month origin V1
## 1: 1 EWR 9524521
## 2: 1 LGA 6359510
## 3: 1 JFK 11304774
## 4: 2 EWR 8725657
## 5: 2 LGA 5917983
## 6: 2 JFK 10331869To also name the new column nicely, say distance instead of the default V1:
flights[, .(distance = sum(distance)), by = c("month", "origin")]## month origin distance
## 1: 1 EWR 9524521
## 2: 1 LGA 6359510
## 3: 1 JFK 11304774
## 4: 2 EWR 8725657
## 5: 2 LGA 5917983
## 6: 2 JFK 10331869For more on basic data.table operations, look at the Introduction to data.table vignette.
As you have probably noticed, the above gave us the sums of distances by months and origins. When creating reports, especially readers coming from Excel may expect 2 extra perks
- Looking at sub-totals and grand total
- Seeing the data in wide format
Since the wide format is just a reshape and data table has the dcast() function for that for quite a while now, we will only briefly show it in practice. The focus of this post will be on the new functionality that was only released in data.table v1.11 in May last year - creating the grand- and sub-totals.
Quick pivot tables with subtotals and a grand total
To create a “classic” pivot table as known from Excel, we need to aggregate the data and also compute the subtotals for all combinations of the selected dimensions and a grand total. In comes cube(), the function that will do just that:
# Get subtotals for origin, month and month&origin with `cube()`:
cubed <- data.table::cube(
flights,
.(distance = sum(distance)),
by = c("month", "origin")
)
cubed## month origin distance
## 1: 1 EWR 9524521
## 2: 1 LGA 6359510
## 3: 1 JFK 11304774
## 4: 2 EWR 8725657
## 5: 2 LGA 5917983
## 6: 2 JFK 10331869
## 7: 1 <NA> 27188805
## 8: 2 <NA> 24975509
## 9: NA EWR 18250178
## 10: NA LGA 12277493
## 11: NA JFK 21636643
## 12: NA <NA> 52164314As we can see, compared to the simple group by summary we did earlier, we have extra rows in the output
- Rows
7,8with months1,2and origin<NA>, <NA>- these are the subtotals per month across all origins - Rows
9,10,11with monthsNA, NA, NAand originsEWR, LGA, JFK- these are the subtotals per origin across all months - Row
12withNAmonth and<NA>origin - this is the Grand total across all origins and months
All that is left to get a familiar pivot table shape is to reshape the data to wide format with the aforementioned dcast() function:
# - Origins in columns, months in rows
data.table::dcast(cubed, month ~ origin, value.var = "distance")## month NA EWR JFK LGA
## 1: NA 52164314 18250178 21636643 12277493
## 2: 1 27188805 9524521 11304774 6359510
## 3: 2 24975509 8725657 10331869 5917983# - Origins in rows, months in columns
data.table::dcast(cubed, origin ~ month, value.var = "distance")## origin NA 1 2
## 1: <NA> 52164314 27188805 24975509
## 2: EWR 18250178 9524521 8725657
## 3: JFK 21636643 11304774 10331869
## 4: LGA 12277493 6359510 5917983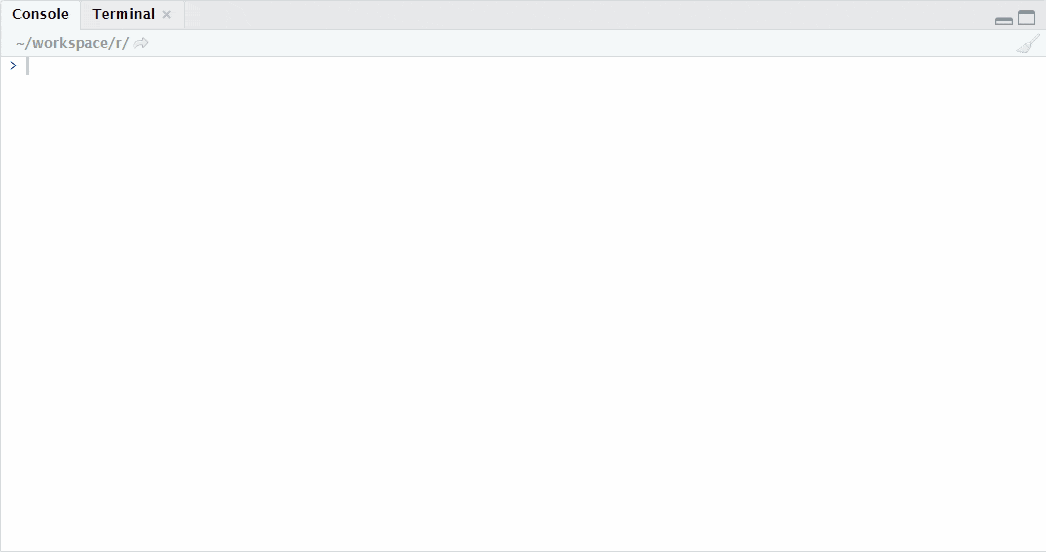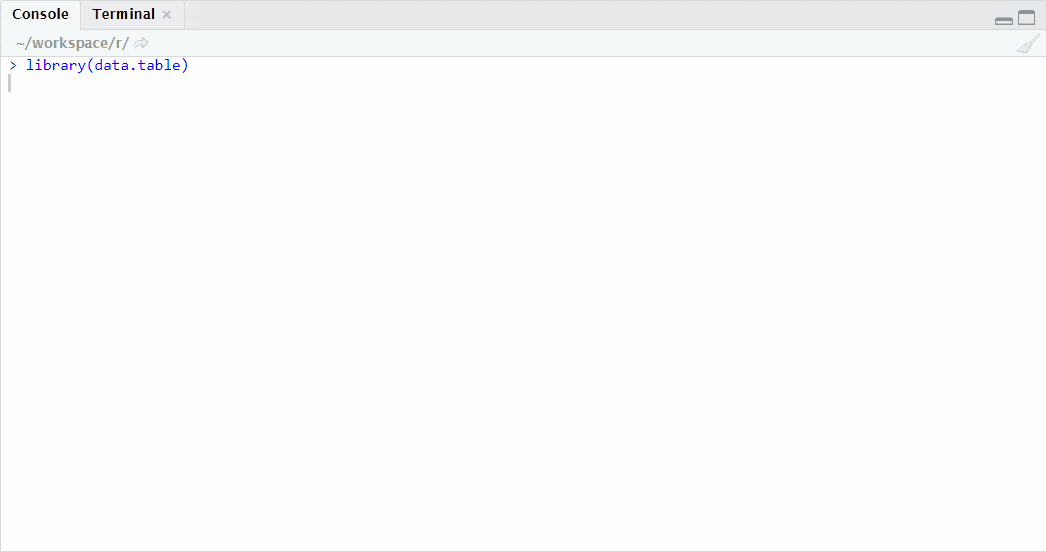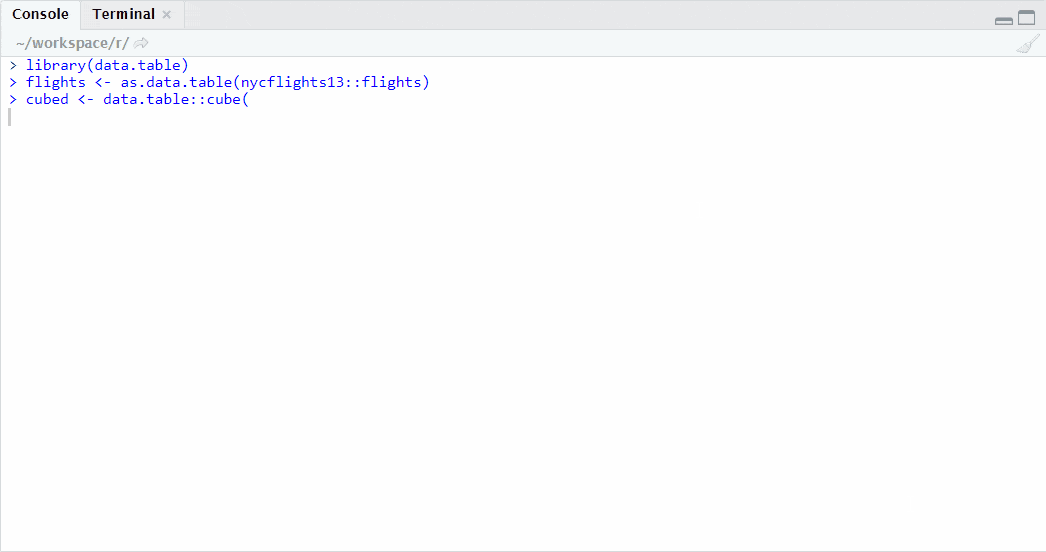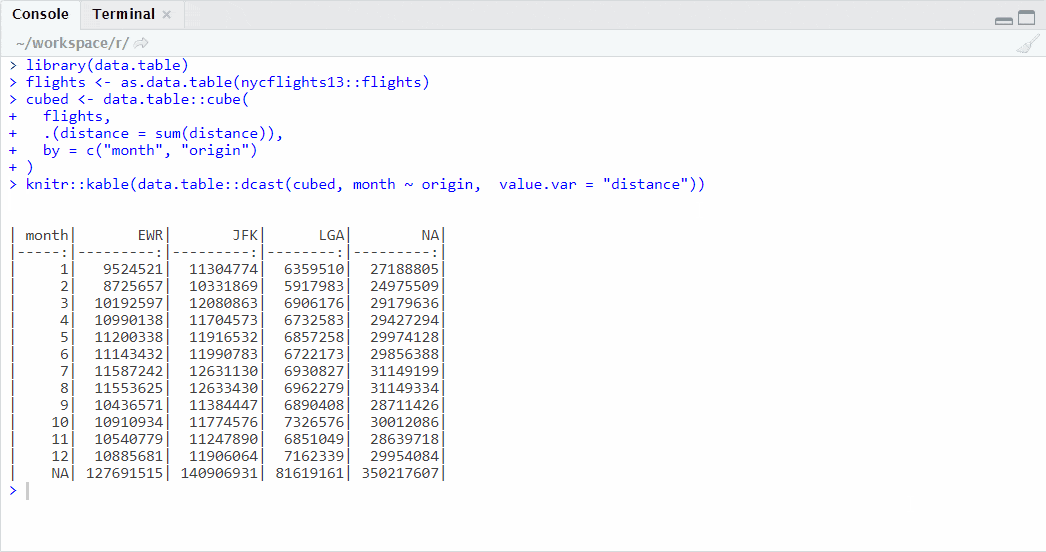
Pivot table with data.table
Using more dimensions
We can use the same approach to create summaries with more than two dimensions, for example, apart from months and origins, we can also look at carriers, simply by adding "carrier" into the by argument:
# With 3 dimensions:
cubed2 <- cube(
flights,
.(distance = sum(distance)),
by = c("month", "origin", "carrier")
)
cubed2## month origin carrier distance
## 1: 1 EWR UA 5084378
## 2: 1 LGA UA 729667
## 3: 1 JFK AA 2013434
## 4: 1 JFK B6 3672655
## 5: 1 LGA DL 1678965
## ---
## 153: NA <NA> F9 174960
## 154: NA <NA> HA 293997
## 155: NA <NA> YV 21526
## 156: NA <NA> OO 733
## 157: NA <NA> <NA> 52164314And dcast() to wide format which suits our needs best:
# For example, with month and carrier in rows, origins in columns:
dcast(cubed2, month + carrier ~ origin, value.var = "distance")## month carrier NA EWR JFK LGA
## 1: NA <NA> 52164314 18250178 21636643 12277493
## 2: NA 9E 1431961 88706 1271194 72061
## 3: NA AA 7171819 789591 3830482 2551746
## 4: NA AS 283436 283436 NA NA
## 5: NA B6 9036256 940582 7062702 1032972
## 6: NA DL 8729015 465275 4963047 3300693
## 7: NA EV 4188259 3940295 48792 199172
## 8: NA F9 174960 NA NA 174960
## 9: NA FL 431194 NA NA 431194
## 10: NA HA 293997 NA 293997 NA
## 11: NA MQ 2439609 293352 425390 1720867
## 12: NA OO 733 NA NA 733
## 13: NA UA 13016872 9770500 1834968 1411404
## 14: NA US 1677108 641427 442107 593574
## 15: NA VX 1463964 NA 1463964 NA
## 16: NA WN 1803605 1037014 NA 766591
## 17: NA YV 21526 NA NA 21526
## 18: 1 <NA> 27188805 9524521 11304774 6359510
## 19: 1 9E 749305 46125 666109 37071
## 20: 1 AA 3773186 415707 2013434 1344045
## 21: 1 AS 148924 148924 NA NA
## 22: 1 B6 4699834 484431 3672655 542748
## 23: 1 DL 4503241 245277 2578999 1678965
## 24: 1 EV 2178833 2067900 24624 86309
## 25: 1 F9 95580 NA NA 95580
## 26: 1 FL 226658 NA NA 226658
## 27: 1 HA 154473 NA 154473 NA
## 28: 1 MQ 1284653 152428 223510 908715
## 29: 1 OO 733 NA NA 733
## 30: 1 UA 6777189 5084378 963144 729667
## 31: 1 US 858820 339595 219387 299838
## 32: 1 VX 788439 NA 788439 NA
## 33: 1 WN 938403 539756 NA 398647
## 34: 1 YV 10534 NA NA 10534
## 35: 2 <NA> 24975509 8725657 10331869 5917983
## 36: 2 9E 682656 42581 605085 34990
## 37: 2 AA 3398633 373884 1817048 1207701
## 38: 2 AS 134512 134512 NA NA
## 39: 2 B6 4336422 456151 3390047 490224
## 40: 2 DL 4225774 219998 2384048 1621728
## 41: 2 EV 2009426 1872395 24168 112863
## 42: 2 F9 79380 NA NA 79380
## 43: 2 FL 204536 NA NA 204536
## 44: 2 HA 139524 NA 139524 NA
## 45: 2 MQ 1154956 140924 201880 812152
## 46: 2 UA 6239683 4686122 871824 681737
## 47: 2 US 818288 301832 222720 293736
## 48: 2 VX 675525 NA 675525 NA
## 49: 2 WN 865202 497258 NA 367944
## 50: 2 YV 10992 NA NA 10992
## month carrier NA EWR JFK LGACustom grouping sets
So far we have focused on the “default” pivot table shapes with all sub-totals and a grand total, however the cube() function could be considered just a useful special case shortcut for a more generic concept - grouping sets. You can read more on grouping sets with MS SQL Server or with PostgreSQL.
The groupingsets() function allows us to create sub-totals on arbitrary groups of dimensions. Custom subtotals are defined by the sets argument, a list of character vectors, each of them defining one subtotal. Now let us have a look at a few practical examples:
Replicate a simple group by, without any subtotals or grand total
For reference, to replicate a simple group by with grouping sets, we could use:
groupingsets(
flights,
j = .(distance = sum(distance)),
by = c("month", "origin", "carrier"),
sets = list(c("month", "origin", "carrier")),
)Which would give the same results as
flights[, .(distance = sum(distance)), by = c("month", "origin", "carrier")]Custom subtotals
To give only the subtotals for each of the dimensions:
groupingsets(
flights,
j = .(distance = sum(distance)),
by = c("month", "origin", "carrier"),
sets = list(
c("month"),
c("origin"),
c("carrier")
)
)## month origin carrier distance
## 1: 1 <NA> <NA> 27188805
## 2: 2 <NA> <NA> 24975509
## 3: NA EWR <NA> 18250178
## 4: NA LGA <NA> 12277493
## 5: NA JFK <NA> 21636643
## 6: NA <NA> UA 13016872
## 7: NA <NA> AA 7171819
## 8: NA <NA> B6 9036256
## 9: NA <NA> DL 8729015
## 10: NA <NA> EV 4188259
## 11: NA <NA> MQ 2439609
## 12: NA <NA> US 1677108
## 13: NA <NA> WN 1803605
## 14: NA <NA> VX 1463964
## 15: NA <NA> FL 431194
## 16: NA <NA> AS 283436
## 17: NA <NA> 9E 1431961
## 18: NA <NA> F9 174960
## 19: NA <NA> HA 293997
## 20: NA <NA> YV 21526
## 21: NA <NA> OO 733
## month origin carrier distanceTo give only the subtotals per combinations of 2 dimensions:
groupingsets(
flights,
j = .(distance = sum(distance)),
by = c("month", "origin", "carrier"),
sets = list(
c("month", "origin"),
c("month", "carrier"),
c("origin", "carrier")
)
)## month origin carrier distance
## 1: 1 EWR <NA> 9524521
## 2: 1 LGA <NA> 6359510
## 3: 1 JFK <NA> 11304774
## 4: 2 EWR <NA> 8725657
## 5: 2 LGA <NA> 5917983
## 6: 2 JFK <NA> 10331869
## 7: 1 <NA> UA 6777189
## 8: 1 <NA> AA 3773186
## 9: 1 <NA> B6 4699834
## 10: 1 <NA> DL 4503241
## 11: 1 <NA> EV 2178833
## 12: 1 <NA> MQ 1284653
## 13: 1 <NA> US 858820
## 14: 1 <NA> WN 938403
## 15: 1 <NA> VX 788439
## 16: 1 <NA> FL 226658
## 17: 1 <NA> AS 148924
## 18: 1 <NA> 9E 749305
## 19: 1 <NA> F9 95580
## 20: 1 <NA> HA 154473
## 21: 1 <NA> YV 10534
## 22: 1 <NA> OO 733
## 23: 2 <NA> US 818288
## 24: 2 <NA> UA 6239683
## 25: 2 <NA> B6 4336422
## 26: 2 <NA> AA 3398633
## 27: 2 <NA> EV 2009426
## 28: 2 <NA> FL 204536
## 29: 2 <NA> MQ 1154956
## 30: 2 <NA> DL 4225774
## 31: 2 <NA> WN 865202
## 32: 2 <NA> 9E 682656
## 33: 2 <NA> VX 675525
## 34: 2 <NA> AS 134512
## 35: 2 <NA> F9 79380
## 36: 2 <NA> HA 139524
## 37: 2 <NA> YV 10992
## 38: NA EWR UA 9770500
## 39: NA LGA UA 1411404
## 40: NA JFK AA 3830482
## 41: NA JFK B6 7062702
## 42: NA LGA DL 3300693
## 43: NA EWR B6 940582
## 44: NA LGA EV 199172
## 45: NA LGA AA 2551746
## 46: NA JFK UA 1834968
## 47: NA LGA B6 1032972
## 48: NA LGA MQ 1720867
## 49: NA EWR AA 789591
## 50: NA JFK DL 4963047
## 51: NA EWR MQ 293352
## 52: NA EWR DL 465275
## 53: NA EWR US 641427
## 54: NA EWR EV 3940295
## 55: NA JFK US 442107
## 56: NA LGA WN 766591
## 57: NA JFK VX 1463964
## 58: NA LGA FL 431194
## 59: NA EWR AS 283436
## 60: NA LGA US 593574
## 61: NA JFK MQ 425390
## 62: NA JFK 9E 1271194
## 63: NA LGA F9 174960
## 64: NA EWR WN 1037014
## 65: NA JFK HA 293997
## 66: NA JFK EV 48792
## 67: NA EWR 9E 88706
## 68: NA LGA 9E 72061
## 69: NA LGA YV 21526
## 70: NA LGA OO 733
## month origin carrier distanceGrand total
To give only the grand total:
groupingsets(
flights,
j = .(distance = sum(distance)),
by = c("month", "origin", "carrier"),
sets = list(
character(0)
)
)## month origin carrier distance
## 1: NA <NA> <NA> 52164314Cube and rollup as special cases of grouping sets
Implementation of cube
We mentioned above that cube() can be considered just a shortcut to a useful special case of groupingsets(). And indeed, looking at the implementation of the data.table method data.table:::cube.data.table, most of what it does is to define the sets to represent the given vector and all of its possible subsets, and passes that to groupingsets():
function (x, j, by, .SDcols, id = FALSE, ...) {
if (!is.data.table(x))
stop("Argument 'x' must be a data.table object")
if (!is.character(by))
stop("Argument 'by' must be a character vector of column names used in grouping.")
if (!is.logical(id))
stop("Argument 'id' must be a logical scalar.")
n = length(by)
keepBool = sapply(2L^(seq_len(n) - 1L), function(k) rep(c(FALSE,
TRUE), times = k, each = ((2L^n)/(2L * k))))
sets = lapply((2L^n):1L, function(j) by[keepBool[j, ]])
jj = substitute(j)
groupingsets.data.table(x, by = by, sets = sets, .SDcols = .SDcols,
id = id, jj = jj)
}This means for example that
cube(flights, sum(distance), by = c("month", "origin", "carrier"))## month origin carrier V1
## 1: 1 EWR UA 5084378
## 2: 1 LGA UA 729667
## 3: 1 JFK AA 2013434
## 4: 1 JFK B6 3672655
## 5: 1 LGA DL 1678965
## ---
## 153: NA <NA> F9 174960
## 154: NA <NA> HA 293997
## 155: NA <NA> YV 21526
## 156: NA <NA> OO 733
## 157: NA <NA> <NA> 52164314Is equivalent to
groupingsets(
flights,
j = .(distance = sum(distance)),
by = c("month", "origin", "carrier"),
sets = list(
c("month", "origin", "carrier"),
c("month", "origin"),
c("month", "carrier"),
c("month"),
c("origin", "carrier"),
c("origin"),
c("carrier"),
character(0)
)
)## month origin carrier distance
## 1: 1 EWR UA 5084378
## 2: 1 LGA UA 729667
## 3: 1 JFK AA 2013434
## 4: 1 JFK B6 3672655
## 5: 1 LGA DL 1678965
## ---
## 153: NA <NA> F9 174960
## 154: NA <NA> HA 293997
## 155: NA <NA> YV 21526
## 156: NA <NA> OO 733
## 157: NA <NA> <NA> 52164314Implementation of rollup
The same can be said about rollup(), another shortcut than can be useful. Instead of all possible subsets, it will create a list representing the vector passed to by and its subsets “from right to left”, including the empty vector to get a grand total. Looking at the implementation of the data.table method data.table::rollup.data.table:
function (x, j, by, .SDcols, id = FALSE, ...) {
if (!is.data.table(x))
stop("Argument 'x' must be a data.table object")
if (!is.character(by))
stop("Argument 'by' must be a character vector of column names used in grouping.")
if (!is.logical(id))
stop("Argument 'id' must be a logical scalar.")
sets = lapply(length(by):0L, function(i) by[0L:i])
jj = substitute(j)
groupingsets.data.table(x, by = by, sets = sets, .SDcols = .SDcols,
id = id, jj = jj)
}For example, the following:
rollup(flights, sum(distance), by = c("month", "origin", "carrier"))Is equivalent to
groupingsets(
flights,
j = .(distance = sum(distance)),
by = c("month", "origin", "carrier"),
sets = list(
c("month", "origin", "carrier"),
c("month", "origin"),
c("month"),
character(0)
)
)References
- Grouping sets, cube and rollup in PostgreSQL
- MS SQL Server
- And in Oracle documentation
- Introduction to data.table
- Efficient reshaping using data.tables